



Die Aufgabenstellung
Eine der größten Herausforderungen für Dachser ist das Klassifizieren von mehrseitigen Dokumenten in verschiedenen Sprachen. Da das Unternehmen grenzüberschreitende Logistiklösungen anbietet, sind viele Dokumente wie Rechnungen, Frachtbriefe und Ursprungszeugnisse zu bearbeiten, die keine einheitliche Datenstruktur aufweisen. Die Vorgabe lautete: Die automatisierte Lösung sollte Dokumente, die in unstrukturierten Formaten – zum Beispiel als PDF-Dateien – eingehen, unabhängig von Sprache und Seitenanzahl nach Inhalt und Kontext effektiv klassifizieren und kategorisieren können.
Häufig gehen bei Dachser auch Dokumentensammlungen ein, die zu einer einzigen PDF-Datei zusammengeführt wurden. Hier müssen die einzelnen Dokumente extrahiert und für die Weiterbearbeitung getrennt werden – eine anspruchsvolle Aufgabe. Von der angebotenen Lösung wurde erwartet, dass sie die in einer PDF-Datei zusammengeführten Dokumente mit Hilfe intelligenter Kriterien erkennt und isoliert und Unterschiede in Dokumentenstruktur, Formatierung und Sprache berücksichtigt.
Da diese Aufgabe spezielles Know-how in Natural Language Processing (NLP), Data Engineering und DevOps voraussetzt, ließ Dachser sich von kreuzwerker unterstützen, um eine Start-of-the-art-Implementierung im Rahmen des AWS-Ökosystems zu gewährleisten.
Die Lösung
Für die komplexe Aufgabenstellung benötigte Dachser eine skalierbare Lösung, die Technologien wie Optische Zeichenerkennung (OCR) und Natürliche Sprachverarbeitung (NLP) nutzt. Die Lösung musste in der Lage sein, große Mengen unstrukturierter Dokumente effizient zu bearbeiten, inhaltlich und sprachlich fehlerfrei zu klassifizieren und in einer einzigen PDF-Datei zusammengeführte Dokumentensammlungen nach intelligenten Kriterien zu trennen.
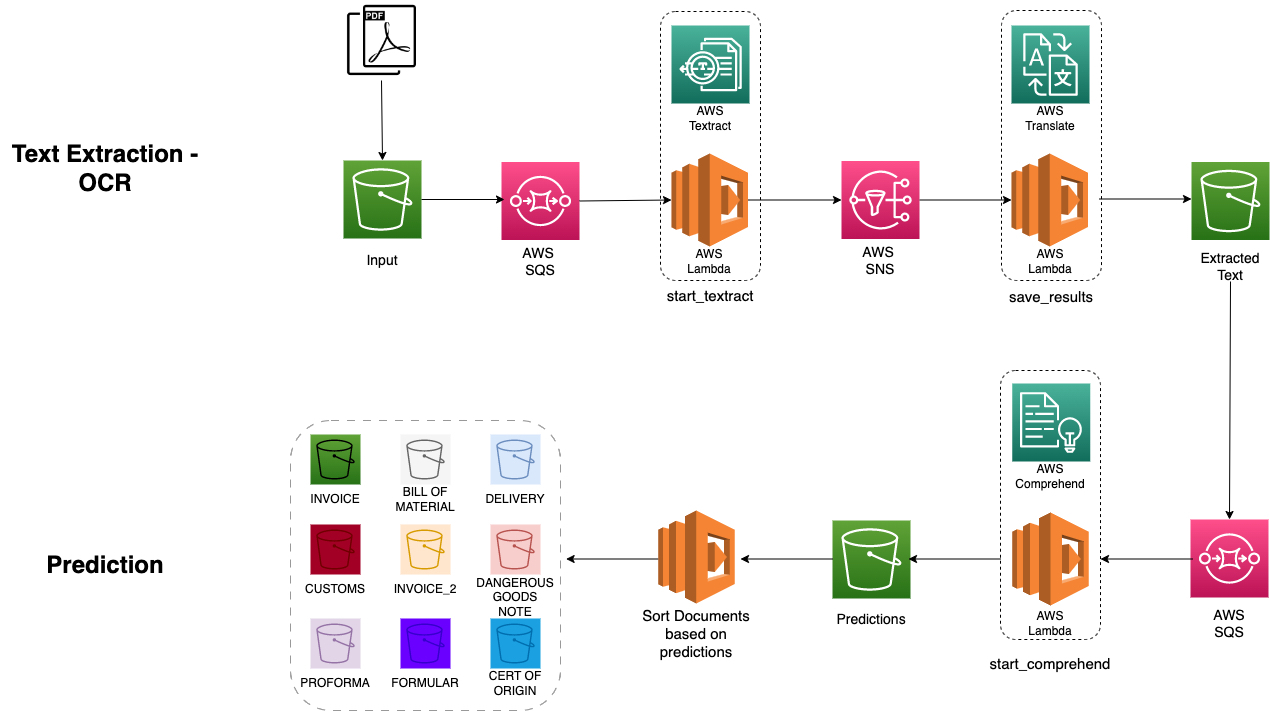
In einem ersten Schritt wurde mit Hilfe von AWS Textract aus von Dachser bereitgestellten Dokumenten Text extrahiert. Das Problem, dass die Dokumente in verschiedenen Sprachen verfasst waren, wurde durch die Übersetzung aller in den Dokumenten extrahierten Texte mit AWS Translate ins Englische gelöst. Somit stand für die anschließenden Analyse- und Klassifizierungsaufgaben eine einheitliche Sprachversion zur Verfügung.
Aus dem übersetzten Text wurde ein Trainingsdatensatz erstellt, mit dem ein benutzerdefiniertes Klassifizierungsmodell angelernt werden konnte. Dieser Datensatz beinhaltete gelabelte Beispiele, wobei jedes Dokument einem bestimmten Dokumententyp zugeordnet wurde.
Der Trainingsdatensatz wurde anschließend an AWS Comprehend weitergeleitet, das auf der Grundlage der gelabelten Daten ein benutzerdefiniertes Klassifizierungsmodell anlernte. Nach dem Anlernen wurde das benutzerdefinierte Klassifizierungsmodell intensiv ausgewertet, um seine Leistung und Effektivität zu beurteilen. Um festzustellen, ob das Modell Dokumente korrekt klassifizieren kann, wurden verschiedene Bewertungsmetriken wie Fehlerfreiheit und F1-Score errechnet. Im letzten Schritt wurde eine Inferenz-Pipeline implementiert, mit der ein eingegebenes Dokument sich anhand der Prognosen des angelernten Modells klassifizieren lässt.
Das folgende Diagramm zeigt die Gesamtarchitektur, bei deren Entwicklung auf Skalierbarkeit und die Einhaltung der Branchenstandards geachtet wurde.
Das Ergebnis
Die entwickelte Lösung kann bis zu 1000 Dokumente gleichzeitig mit einer Genauigkeit von 95 % klassifizieren. Um Komplexität, Entwicklungsdauer und Betriebsaufwand zu reduzieren, wurde die gesamte Lösung mit Hilfe der von AWS bereitgestellten serverlosen Dienste erstellt. Zusammen mit der Dokumentation ermöglicht dieses Konzept ein wartungsfreundliches Produkt und eröffnet Spielräume für weitere Optimierungsschritte, für die kein Team von ausgewiesenen Machine-Learning-Experten benötigt wird.
Fazit
Der globale Logistikdienstleister Dachser testete in Kooperation mit kreuzwerker eine skalierbare Lösung im AWS-Ökosystem, um seine Dokumenten-Managementprozesse zu optimieren. Mit Hilfe von OCR- und NLP-Technologien klassifiziert die Lösung mehrseitige Dokumente in verschiedenen Sprachen fehlerfrei und extrahiert in PDF-Dateien zusammengeführte Dokumente als Einzeldokumente. Dank der Nutzung von AWS Textract für die Textextraktion und AWS Comprehend für das Anlernen eines benutzerdefinierten Klassifizierungsmodells konnte Dachser mit Unterstützung von kreuzwerker in wenigen Wochen eine intelligente Dokumentenverarbeitung aufbauen, die den neuesten technologischen Standards entspricht.